DLPFC data example
Lulu Shang, Xiang Zhou
2022-01-27
Last updated: 2022-03-22
Checks: 7 0
Knit directory: Tutorial/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20220106) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 251c36f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/_main.html
Untracked files:
Untracked: code/Simulation.R
Untracked: code/SpatialPCA.R
Untracked: code/SpatialPCA_EstimateLoading.R
Untracked: code/SpatialPCA_SpatialPCs.R
Untracked: code/SpatialPCA_buildKernel.R
Untracked: code/SpatialPCA_highresolution.R
Untracked: code/SpatialPCA_utilties.R
Untracked: data/LIBD_sample9.RData
Untracked: data/Puck_200115_08_count_location.RData
Untracked: data/ST_data.RData
Untracked: data/Vizgen_Merfish_count_location.RData
Untracked: data/slideseq.rds
Untracked: docs.zip
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/DLPFC.Rmd) and HTML (docs/DLPFC.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 251c36f | shangll123 | 2022-03-22 | Publish SpatialPCA tutorial |
library(SpatialPCA)
library(ggplot2)Loading data
We used sample 151673 in DLPFC data as a main example which contains expression measurement of 33,538 genes on 3,639 spots. All 12 DLPFC samples can be downloaded from their original study spatialLIBD. We also saved the raw data that we used in our examples in RData format, which can be downloaded from here.
sample_names=c("151507", "151508", "151509", "151510", "151669", "151670", "151671" ,"151672","151673", "151674" ,"151675" ,"151676")
i=9 # Here we take the 9th sample as example, in total there are 12 samples (numbered as 1-12), the user can test on other samples if needed.
clusterNum=c(7,7,7,7,5,5,5,5,7,7,7,7) # each sample has different ground truth cluster number
load(paste0("../data/LIBD_sample",i,".RData"))
print(dim(count_sub)) # The count matrix
print(dim(xy_coords)) # The x and y coordinates. We flipped the y axis for visualization.Create SpatialPCA Object
SpatialPCA takes the raw count data and location coordinates as inputs. We first create a S4 object in the CreateSpatialPCAObject function, then select spatial genes using spark (in Visium data or ST data with small sample size) or sparkx (in Slide-seq or Slide-seq V2 data with large sample size).
# location matrix: n x 2, count matrix: g x n.
# here n is spot number, g is gene number.
xy_coords = as.matrix(xy_coords)
rownames(xy_coords) = colnames(count_sub) # the rownames of location should match with the colnames of count matrix
LIBD = CreateSpatialPCAObject(counts=count_sub, location=xy_coords, project = "SpatialPCA",gene.type="spatial",sparkversion="spark",numCores_spark=5,gene.number=3000, customGenelist=NULL,min.loctions = 20, min.features=20)Estimate spatial PCs
SpatialPCA constructs a kernel matrix to model the spatial pattern of spatial PCs.
LIBD = SpatialPCA_buildKernel(LIBD, kerneltype="gaussian", bandwidthtype="SJ",bandwidth.set.by.user=NULL)
LIBD = SpatialPCA_EstimateLoading(LIBD,fast=FALSE,SpatialPCnum=20)
LIBD = SpatialPCA_SpatialPCs(LIBD, fast=FALSE)The bandwidth selection is critical for the kernel matrix. The type of bandwidth to be used in Gaussian kernel, “SJ” for Sheather & Jones (1991) method, usually used in small size datasets; “Silverman” for Silverman’s ‘rule of thumb’ method (1986), usually used in large size datasets. The user can also specify the bandwidth on their own if needed. After specifying the kernel matrix, SpatialPCA estimates the loading matrix and the spatial PCs. The users can select “TRUE” if they want to use low-rank approximation on the kernel matrix to accelerate the algorithm, otherwise select “FALSE”.
Detect spatial domains
SpatialPCA detects spatial domains through clustering on the spatial PCs. In Visium or ST data, we use walktrap clustering method. We also provide an optional refine step to obtain more continuous and smooth spatial domains.
clusterlabel= walktrap_clustering(clusternum=clusterNum[i],latent_dat=LIBD@SpatialPCs,knearest=70 )
# here for all 12 samples in LIBD, we set the same k nearest number in walktrap_clustering to be 70.
# for other Visium or ST data, the user can also set k nearest number as round(sqrt(dim(SpatialPCAobject@SpatialPCs)[2])) by default.
clusterlabel_refine = refine_cluster_10x(clusterlabels=clusterlabel,location=LIBD@location,shape="hexagon")Spatial domains detected by SpatialPCA.
cbp=c("#9C9EDE" ,"#5CB85C" ,"#E377C2", "#4DBBD5" ,"#FED439" ,"#FF9896", "#FFDC91")
plot_cluster(location=xy_coords,clusterlabel=clusterlabel_refine,pointsize=1.5,textsize=20 ,title_in=paste0("SpatialPCA"),color_in=cbp)
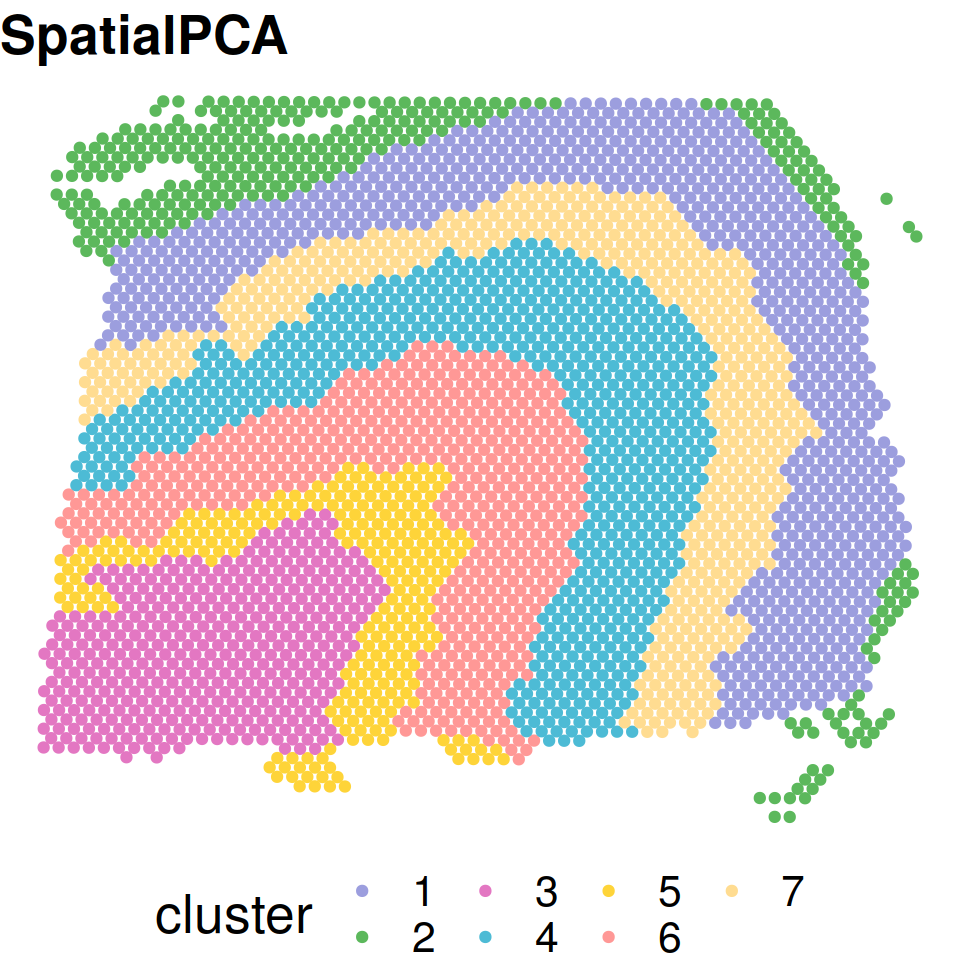
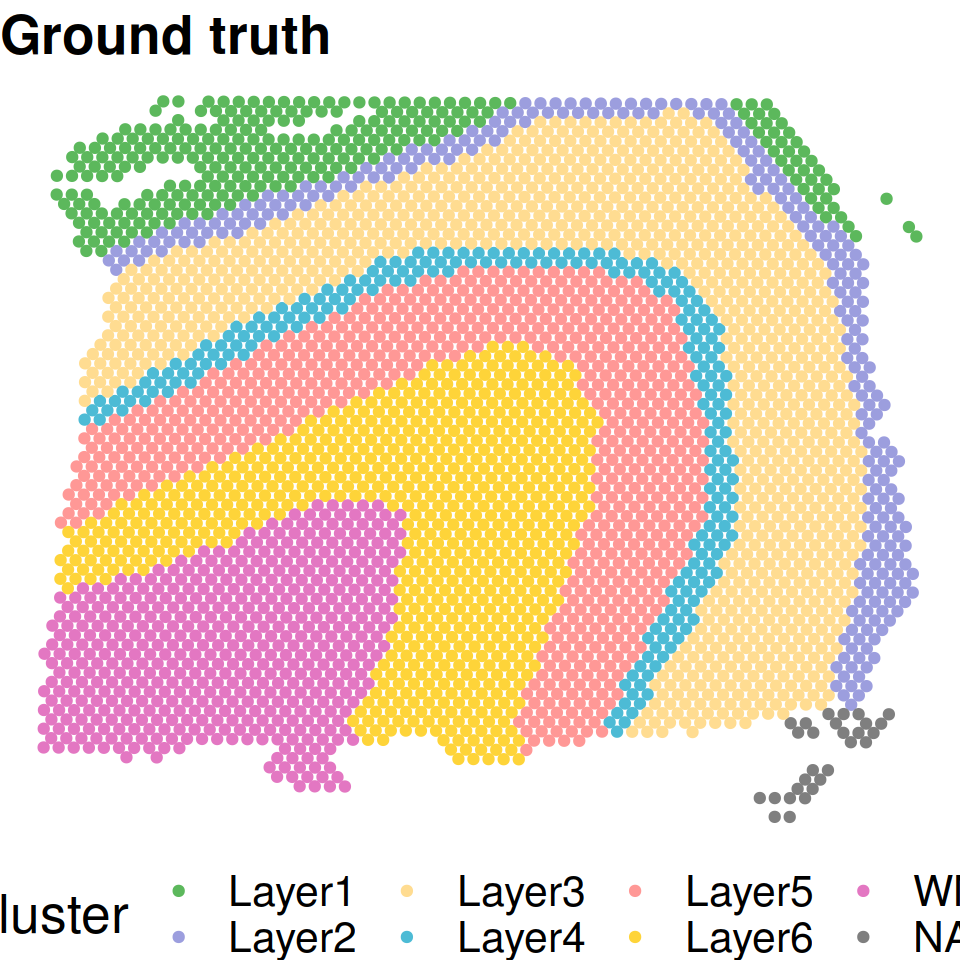
Spatial domains with ground truth annotations.
truth = KRM_manual_layers_sub$layer_guess_reordered[match(colnames(LIBD@normalized_expr),colnames(count_sub))]
cbp=c("#5CB85C" ,"#9C9EDE" ,"#FFDC91", "#4DBBD5" ,"#FF9896" ,"#FED439", "#E377C2", "#FED439")
plot_cluster(location=xy_coords,truth,pointsize=1.5,textsize=20 ,title_in=paste0("Ground truth"),color_in=cbp)
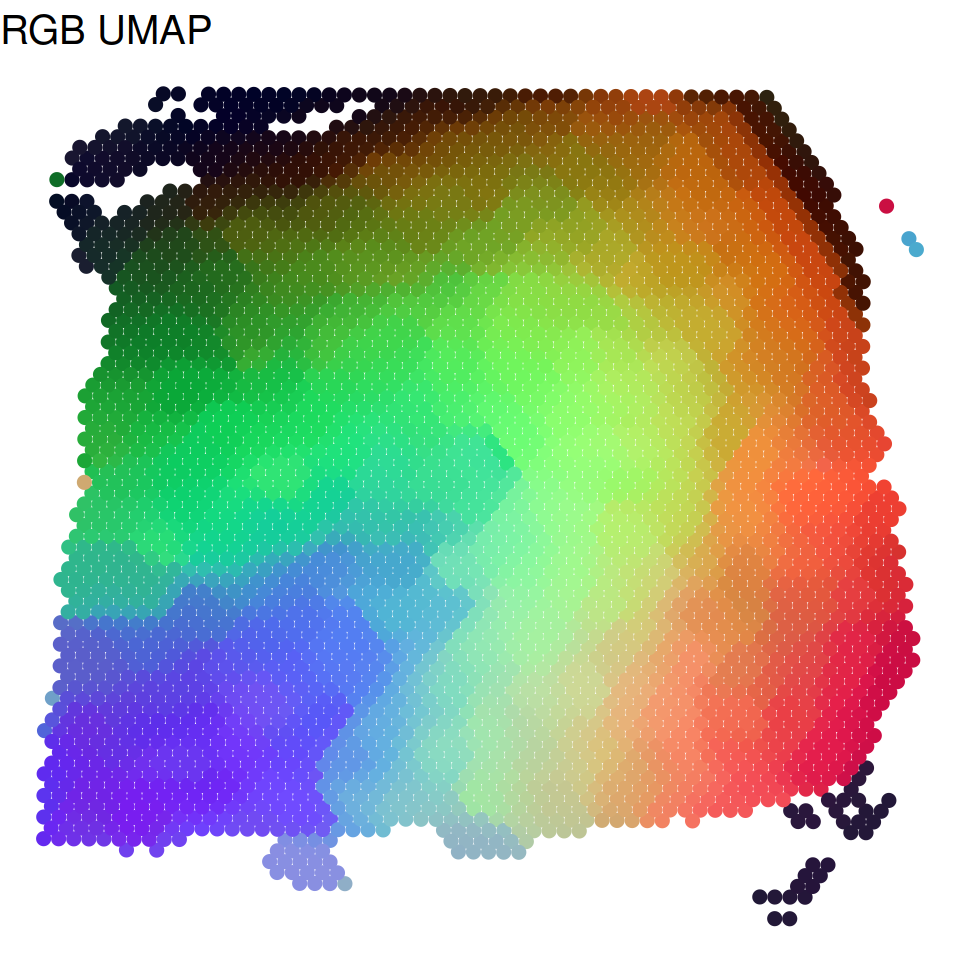
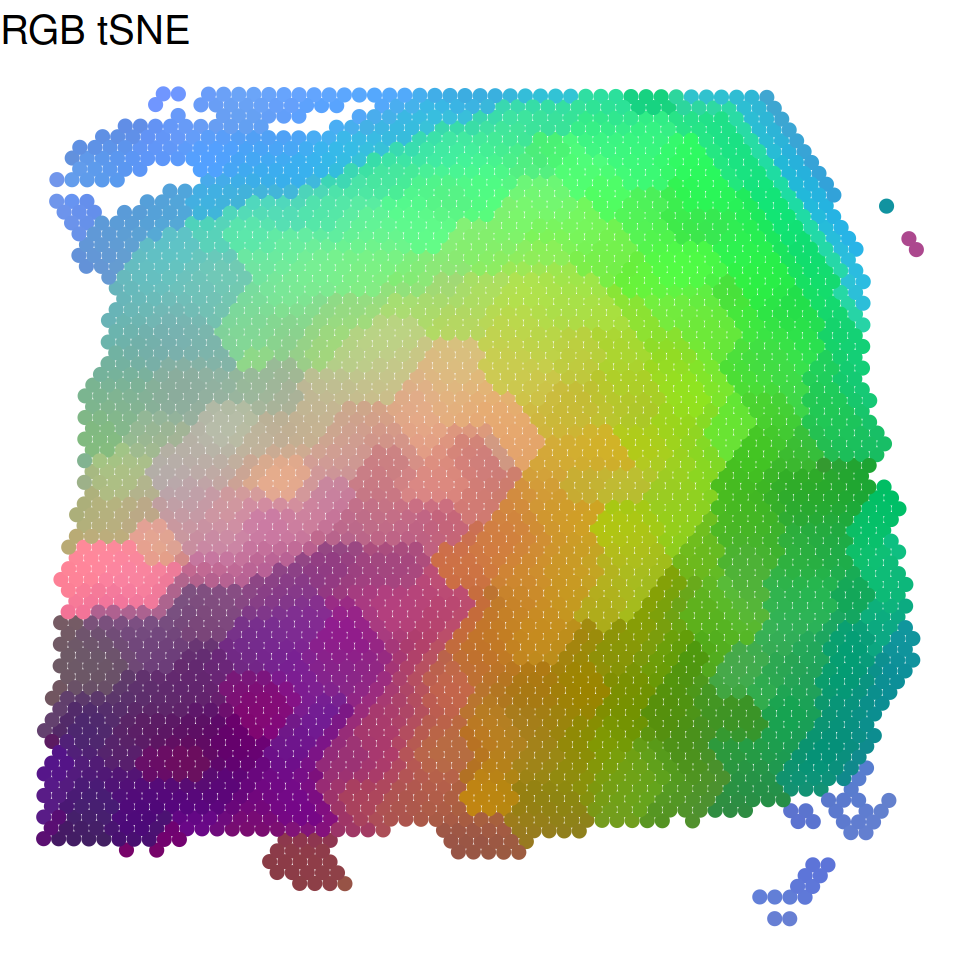
Visualization tSNE and UMAP plots
We summarized the inferred low dimensional components into three UMAP or tSNE components and visualized the three resulting components with red/green/blue (RGB) colors in the RGB plot.
set.seed(1234)
p_UMAP = plot_RGB_UMAP(LIBD@location,LIBD@SpatialPCs,pointsize=2,textsize=15)
p_UMAP$figure
p_tSNE = plot_RGB_tSNE(LIBD@location,LIBD@SpatialPCs,pointsize=2,textsize=15)
p_tSNE$figure
Trajectory inference
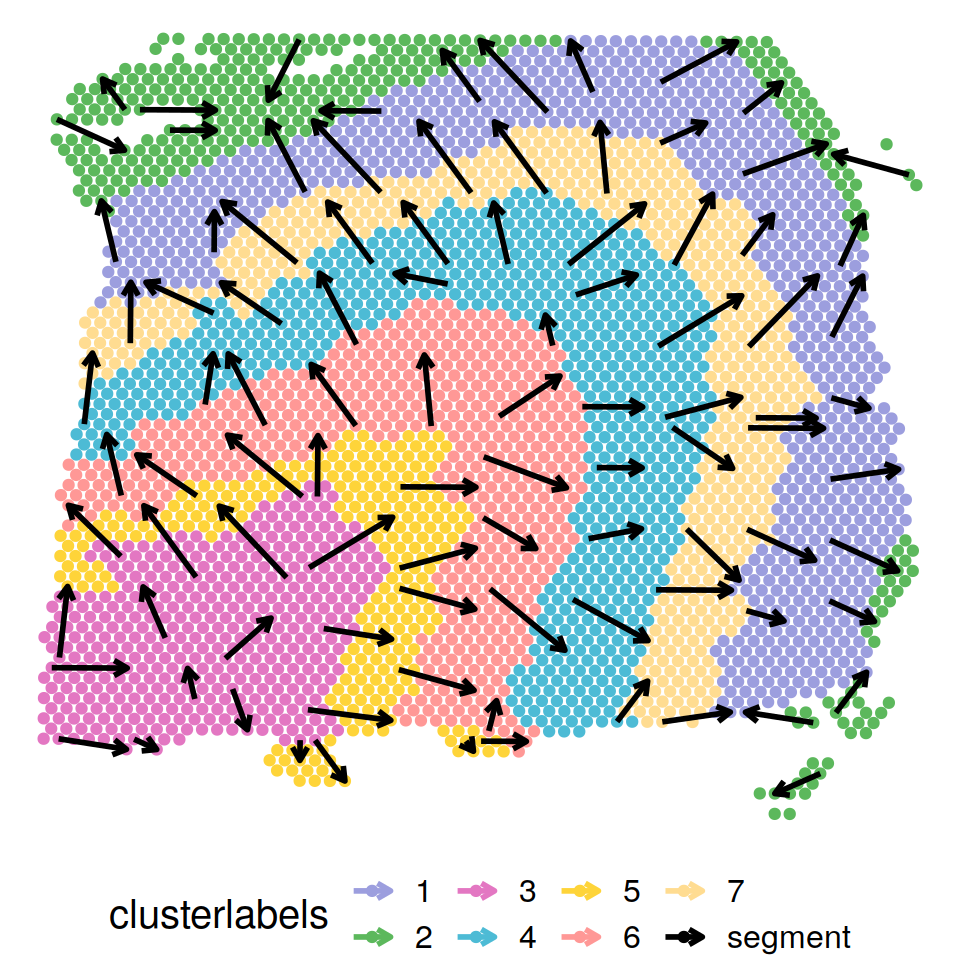
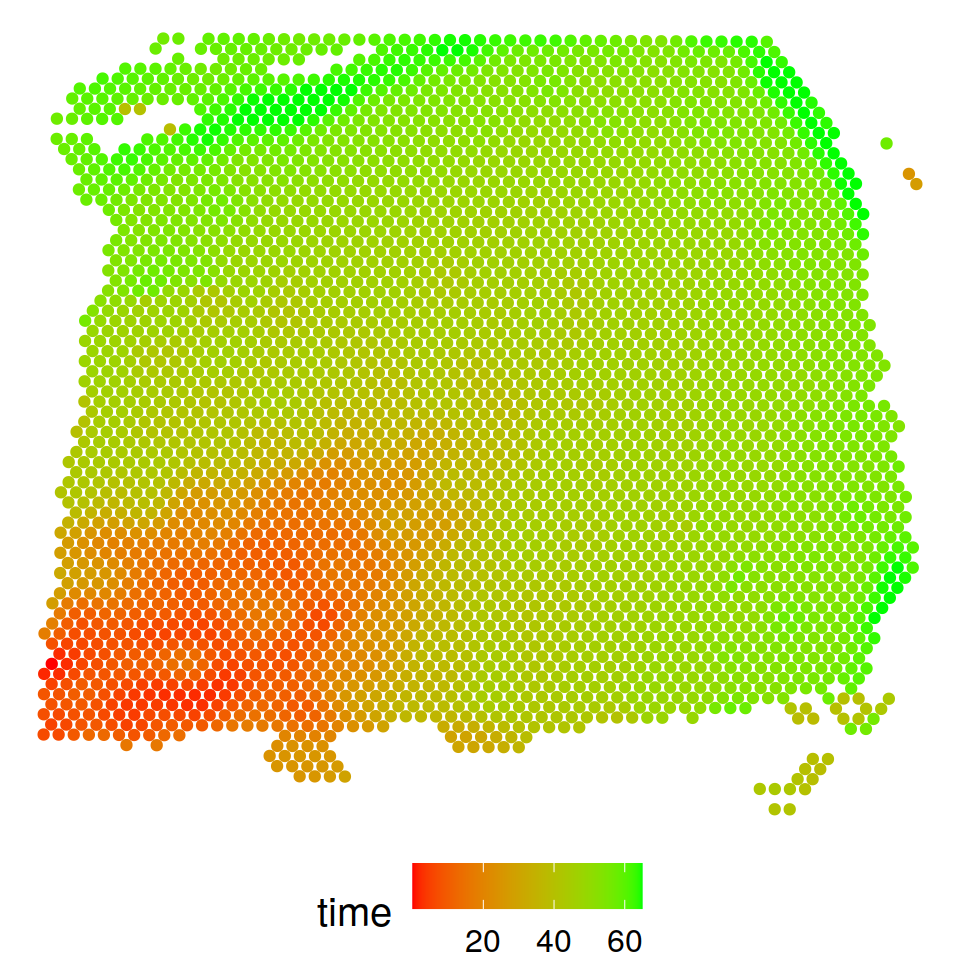
The detected trajectory projects from inner to outer layers and captures the well-known “inside-out” pattern of corticogenesis: new neurons are born in the ventricular zone, migrate along the radial glia fibers in a vertical fashion towards the marginal zone on the outskirt of the cortex, and pass the old neurons in the existing layers to form the new cortical layers.
library(slingshot)
sim<- SingleCellExperiment(assays = count_sub)
reducedDims(sim) <- SimpleList(DRM = t(LIBD@SpatialPCs))
colData(sim)$clusterlabel <- factor(clusterlabel_refine)
sim <-slingshot(sim, clusterLabels = 'clusterlabel', reducedDim = 'DRM',start.clus="3" )
# in this data we set white matter region as start cluster, one can change to their preferred start region
summary(sim@colData@listData)
pseudotime_traj1 = sim@colData@listData$slingPseudotime_1 # in this data only one trajectory was inferred
gridnum = 10
color_in = c("#9C9EDE" ,"#5CB85C" ,"#E377C2", "#4DBBD5" ,"#FED439" ,"#FF9896", "#FFDC91","black")
p_traj1 = plot_trajectory(pseudotime_traj1, LIBD@location,clusterlabel_refine,gridnum,color_in,pointsize=1.5 ,arrowlength=0.2,arrowsize=1,textsize=15 )
p_traj1$Arrowoverlay1
p_traj1$Pseudotime
sessionInfo()R version 4.1.3 (2022-03-10)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 18.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/libopenblasp-r0.2.20.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggplot2_3.3.5 SpatialPCA_1.2.0 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Seurat_4.0.5 Rtsne_0.15 colorspace_2.0-2
[4] deldir_1.0-6 ellipsis_0.3.2 ggridges_0.5.3
[7] rprojroot_2.0.2 RcppArmadillo_0.10.7.0.0 fs_1.5.0
[10] spatstat.data_2.1-0 leiden_0.3.9 listenv_0.8.0
[13] matlab_1.0.2 ggrepel_0.9.1 RSpectra_0.16-0
[16] fansi_0.5.0 codetools_0.2-18 splines_4.1.3
[19] doParallel_1.0.16 knitr_1.36 polyclip_1.10-0
[22] jsonlite_1.7.2 umap_0.2.7.0 ica_1.0-2
[25] cluster_2.1.2 png_0.1-7 uwot_0.1.10
[28] spatstat.sparse_2.0-0 shiny_1.7.1 sctransform_0.3.2
[31] compiler_4.1.3 httr_1.4.2 assertthat_0.2.1
[34] SeuratObject_4.0.2 Matrix_1.3-4 fastmap_1.1.0
[37] lazyeval_0.2.2 later_1.3.0 htmltools_0.5.2
[40] tools_4.1.3 igraph_1.2.7 gtable_0.3.0
[43] glue_1.4.2 RANN_2.6.1 reshape2_1.4.4
[46] dplyr_1.0.7 Rcpp_1.0.7 scattermore_0.7
[49] jquerylib_0.1.4 vctrs_0.3.8 SPARK_1.1.0
[52] nlme_3.1-153 iterators_1.0.13 lmtest_0.9-38
[55] xfun_0.27 stringr_1.4.0 globals_0.14.0
[58] mime_0.12 miniUI_0.1.1.1 CompQuadForm_1.4.3
[61] lifecycle_1.0.1 irlba_2.3.3 goftest_1.2-3
[64] future_1.22.1 MASS_7.3-54 zoo_1.8-9
[67] scales_1.1.1 spatstat.core_2.3-0 spatstat.utils_2.2-0
[70] doSNOW_1.0.19 promises_1.2.0.1 parallel_4.1.3
[73] RColorBrewer_1.1-2 yaml_2.2.1 reticulate_1.22
[76] pbapply_1.5-0 gridExtra_2.3 sass_0.4.0
[79] rpart_4.1-15 stringi_1.7.5 foreach_1.5.1
[82] rlang_0.4.12 pkgconfig_2.0.3 matrixStats_0.61.0
[85] pracma_2.3.3 evaluate_0.14 lattice_0.20-45
[88] tensor_1.5 ROCR_1.0-11 purrr_0.3.4
[91] patchwork_1.1.1 htmlwidgets_1.5.4 pdist_1.2
[94] cowplot_1.1.1 tidyselect_1.1.1 parallelly_1.28.1
[97] RcppAnnoy_0.0.19 plyr_1.8.6 magrittr_2.0.1
[100] R6_2.5.1 snow_0.4-4 generics_0.1.1
[103] DBI_1.1.1 withr_2.4.2 mgcv_1.8-38
[106] pillar_1.6.4 whisker_0.4 fitdistrplus_1.1-6
[109] abind_1.4-5 survival_3.2-13 tibble_3.1.5
[112] future.apply_1.8.1 crayon_1.4.1 KernSmooth_2.23-20
[115] utf8_1.2.2 spatstat.geom_2.3-0 plotly_4.10.0
[118] rmarkdown_2.11 grid_4.1.3 data.table_1.14.2
[121] git2r_0.28.0 digest_0.6.28 pbmcapply_1.5.0
[124] xtable_1.8-4 tidyr_1.1.4 httpuv_1.6.3
[127] openssl_1.4.5 munsell_0.5.0 viridisLite_0.4.0
[130] bslib_0.3.1 askpass_1.1